El problema
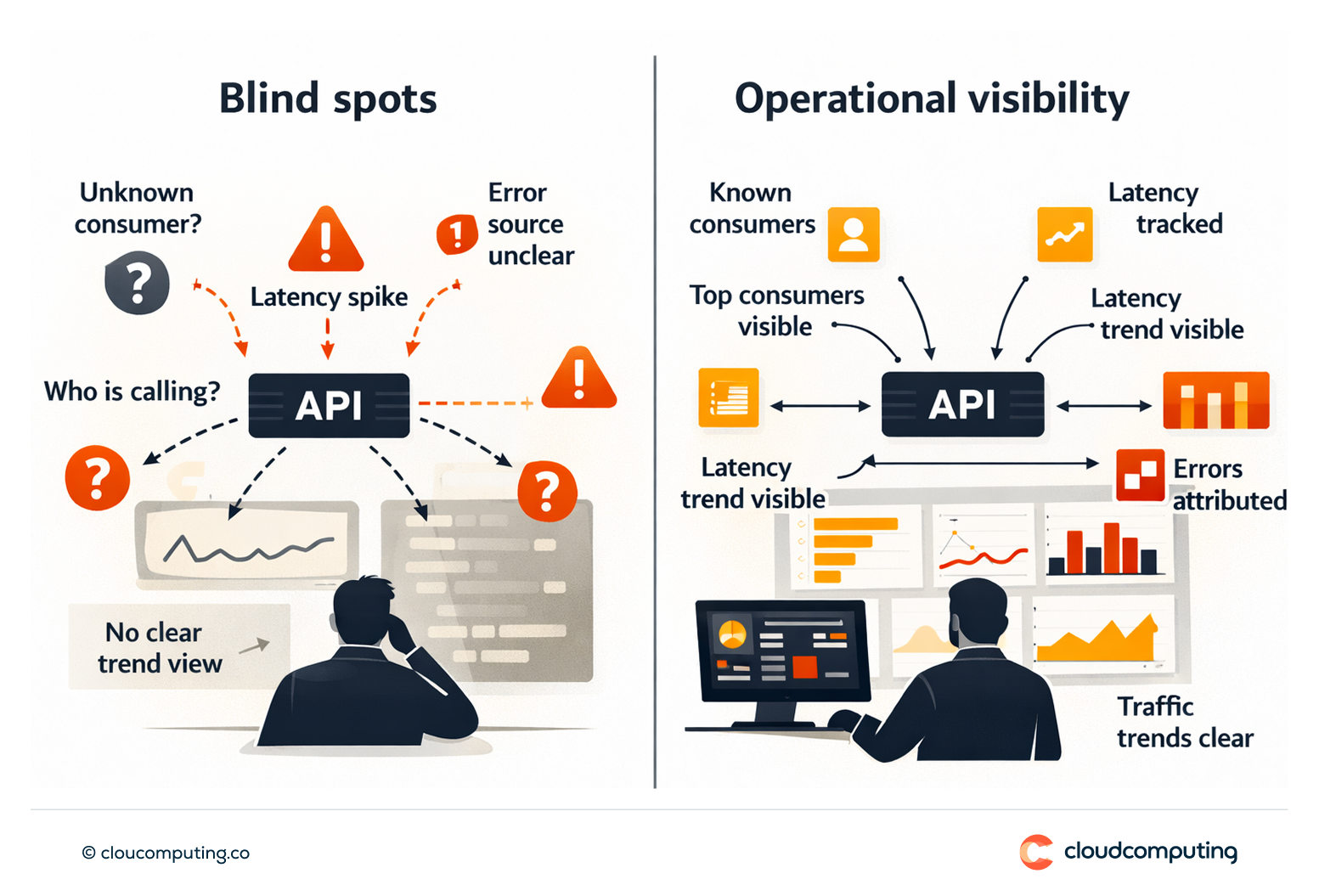
El análisis de causa raíz es lento porque la visibilidad es limitada.
Los equipos no pueden ver con fiabilidad quién llama a qué, por qué aumenta la latencia o qué consumidores están generando errores.
Sin dashboards y patrones de trazabilidad, el rendimiento y la planificación de capacidad siguen siendo reactivos.
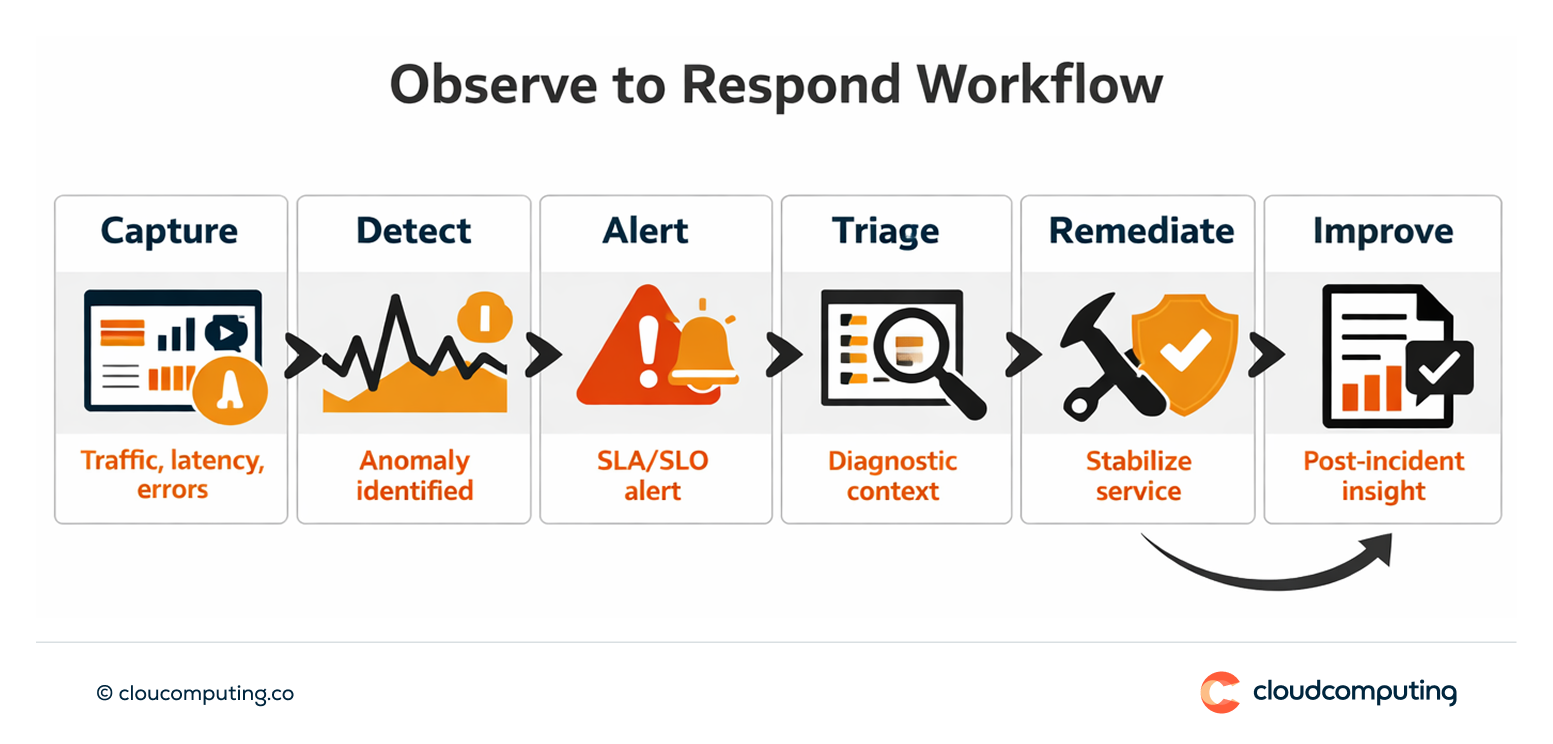
Cómo lo resolvemos: implantar dashboards de analítica API, patrones de trazabilidad, visibilidad de SLA/SLO y alertado operativo.
Implantamos observabilidad para los programas API, de modo que el rendimiento y los incidentes puedan gestionarse con datos y no con suposiciones.
- Analítica y dashboards
Hacer seguimiento del tráfico, los consumidores, la latencia, los errores y los resultados de las políticas. - Patrones de trazabilidad
Implantar correlación y trazabilidad para conectar los eventos del gateway con el comportamiento del backend. - Reporting de SLA/SLO y alertado
Definir umbrales y flujos de alertado alineados con los objetivos de servicio.
Resultado esperado
- Respuesta a incidentes más rápida gracias a una visibilidad y un alertado más claros
- Mejor rendimiento al identificar rutas de alta latencia y cuellos de botella
- Mejor planificación de capacidad utilizando datos de uso y tendencias
- Mayor responsabilidad al disponer de visibilidad sobre consumidores y propietarios
Quick Answers
¿Por qué son difíciles de diagnosticar los incidentes API?
Porque a menudo faltan visibilidad sobre consumidores, atribución de latencia y contexto de error.
¿Qué deberían mostrar primero las analíticas?
Los principales consumidores, la distribución de la latencia, las tendencias de error y los resultados de las políticas en el gateway.
¿Cómo ayudan los SLA/SLO?
Definen expectativas de servicio y permiten alertar de forma proactiva antes de que se produzca una disrupción relevante.