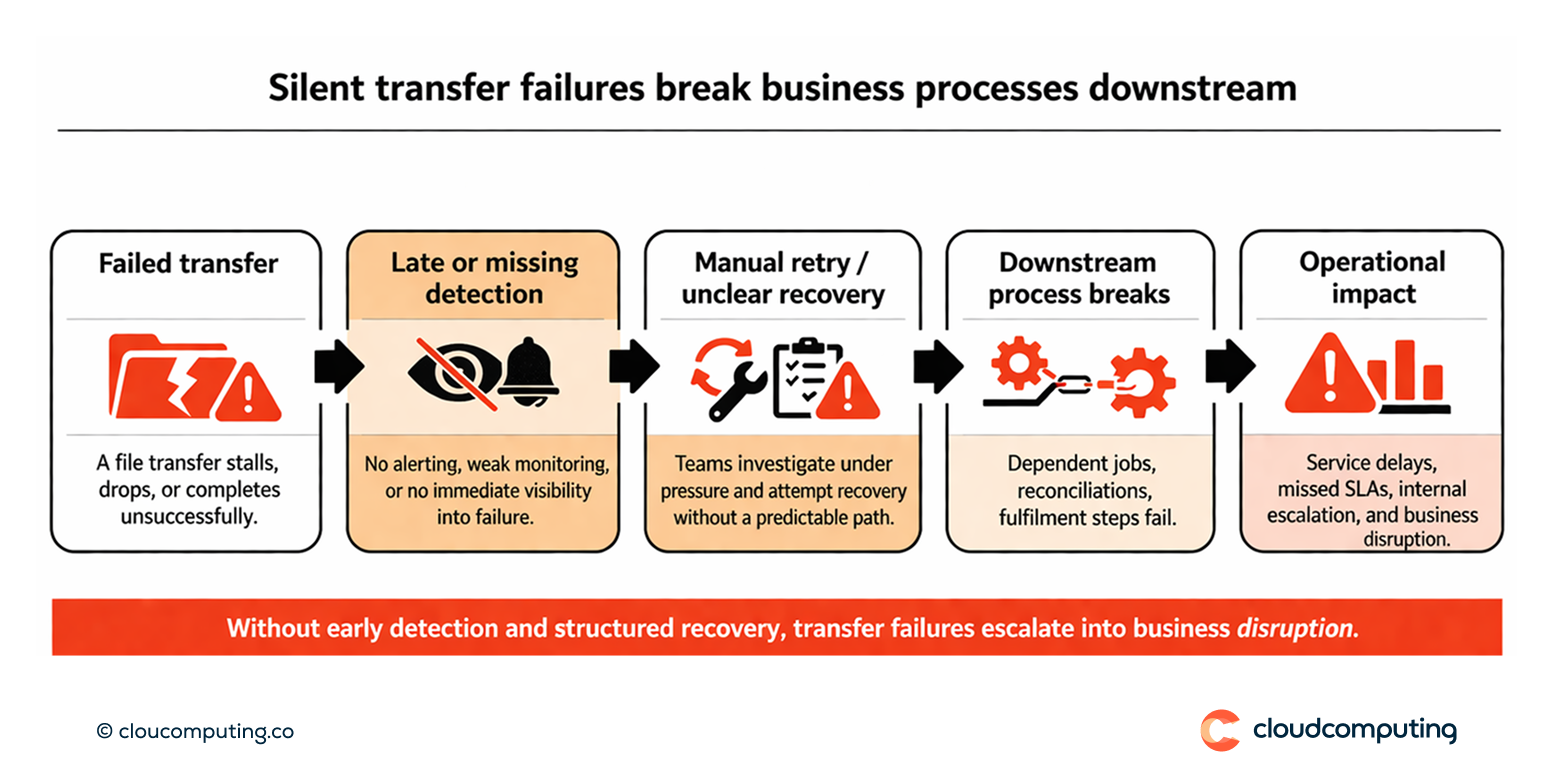
El problema
Las transferencias fallan en silencio, los reintentos son manuales y los procesos de negocio downstream se rompen.
Sin checkpointing, reinicio y gestión coherente de errores, los equipos detectan los fallos tarde y tienen que reconstruir lo ocurrido bajo presión.
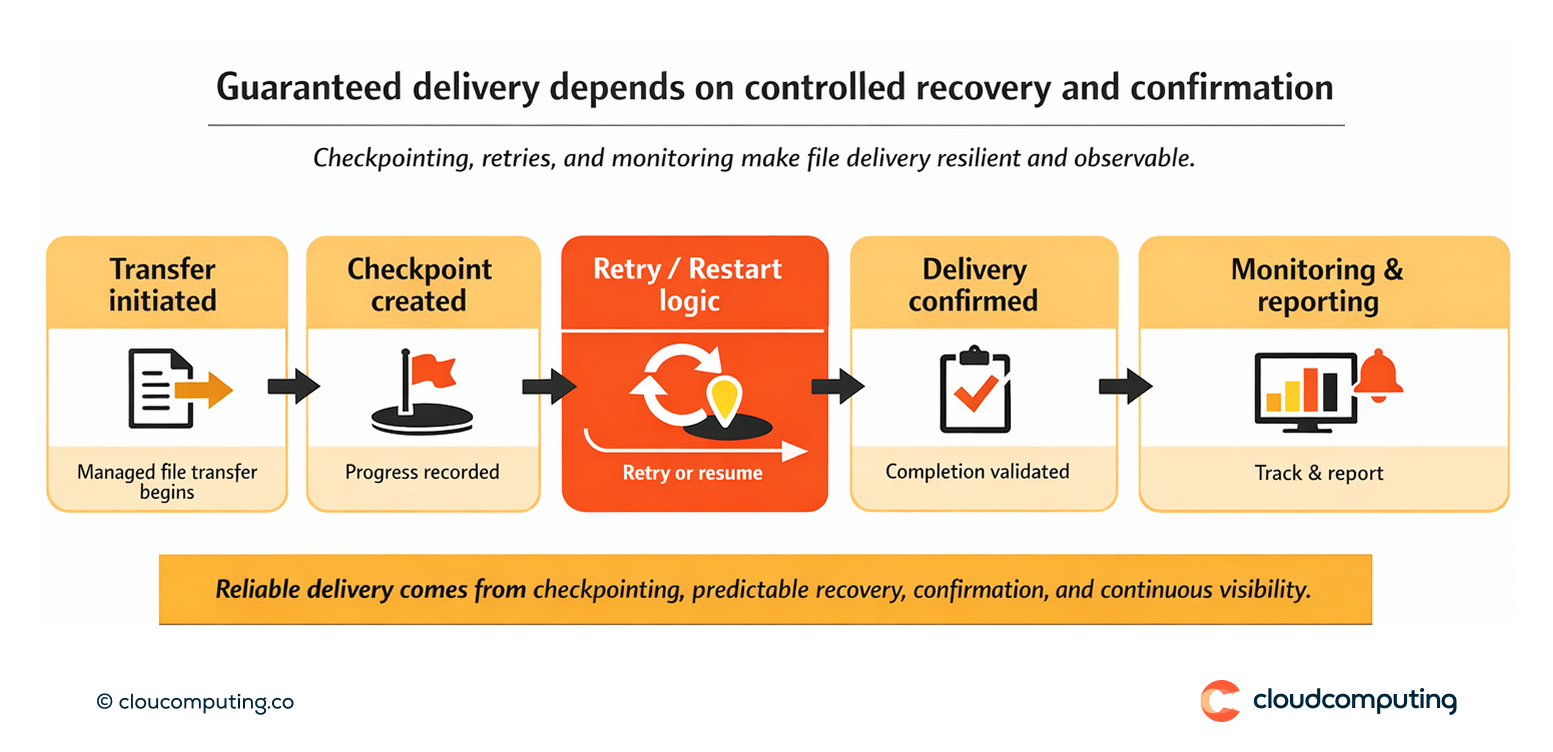
Cómo lo resolvemos: configuramos entrega garantizada con reintentos, checkpoint/restart y monitorización proactiva en Axway MFT.
Implantamos controles de fiabilidad para que las transferencias sean resilientes, observables y recuperables.
- Patrones de entrega garantizada
Configuramos entrega fiable con reintentos y una gestión robusta de fallos. - Checkpoint/restart
Habilitamos puntos de control para que las transferencias grandes puedan reanudarse sin empezar desde cero. - Monitorización proactiva
Monitorizamos la salud de las transferencias y activamos alertas en función de umbrales de SLA.
Resultado esperado
- Menos transferencias fallidas gracias a controles de entrega resilientes
- Mayor fiabilidad del servicio con un comportamiento predecible de reintento y recuperación
- Menor disrupción del negocio al evitar roturas silenciosas de procesos
- Recuperación más rápida mediante checkpoint/restart y alertas proactivas
Respuestas rápidas
¿Qué es la entrega garantizada en MFT?
Son controles de fiabilidad que aseguran que las transferencias se completen correctamente o se recuperen de forma predecible con reintentos y reinicio.
¿Por qué fallan en silencio las transferencias?
Porque los scripts y las herramientas ad hoc suelen carecer de monitorización, alertas y una gestión consistente de errores.
¿Qué resuelve checkpoint/restart?
Permite reanudar transferencias grandes tras una interrupción sin empezar desde el principio.