The Problem
Teams lack a single operational view of file transfer services.
Issues are detected late, root cause is unclear, and resolution is slow because monitoring is fragmented across tools and scripts.
SLAs are hard to manage without dashboards that show service health and transfer outcomes.
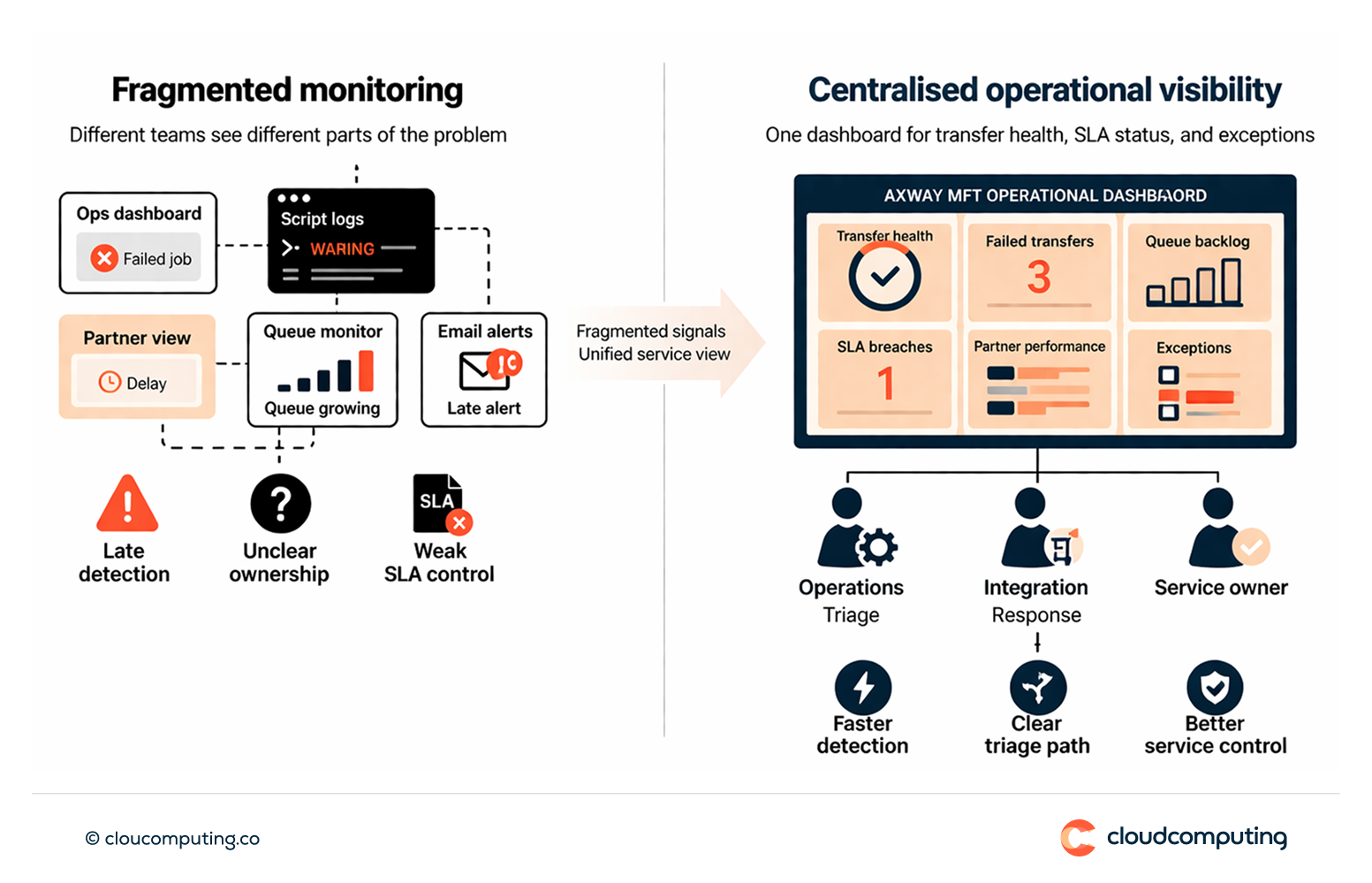
How we solve it: Consolidate monitoring and alerting, define SLAs, and create operational dashboards for Axway MFT services.
We implement monitoring as an operational capability: alerting, dashboards, escalation paths, and measurable SLAs.
- Single operational view
Consolidate transfer health, queue status, failures, and SLA breaches into unified dashboards. - Alerting and escalation
Configure alerts aligned to operational thresholds and define escalation workflows. - SLA and reporting model
Define SLAs per route or partner and report performance consistently.
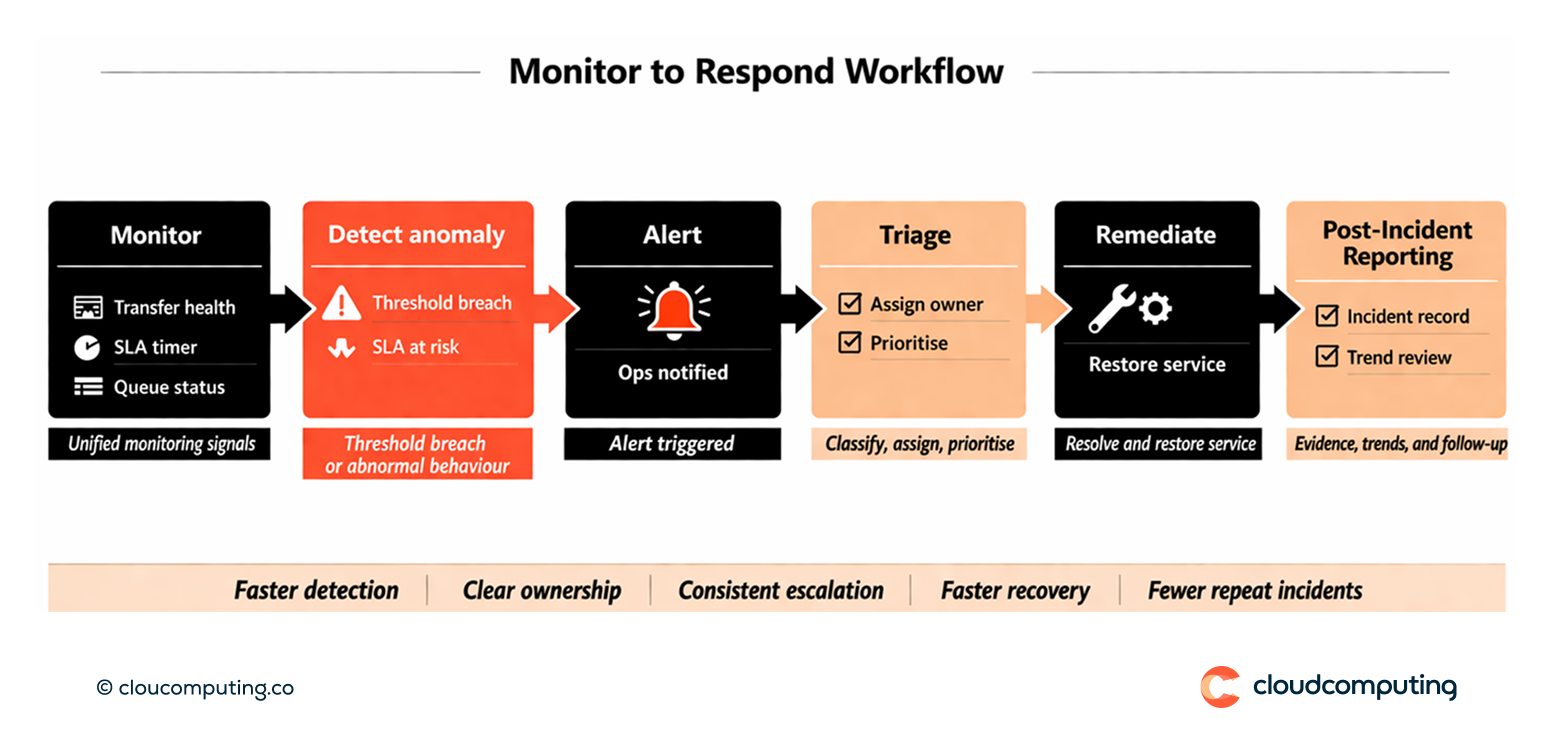
Expected outcome
- Faster incident resolution through early detection and clear triage paths
- Better service control with SLAs and operational dashboards
- Improved uptime by reducing repeated failure patterns
- Reduced operational load through predictable monitoring and response processes
Quick Answers
What does centralised monitoring provide?
A single view of transfer health, failures, and SLA performance across routes and partners.
Why is alerting critical for MFT?
Because late detection creates downstream business disruption and increases recovery effort.
What should dashboards show?
Service health, failed transfers, backlog/queues, SLA breaches, and partner-specific performance.